 CV
CV Github
Github Google Scholar
Google Scholar
Currently, I am a Ph.D student in the Computer Science department at Stanford University advised by Stefano Ermon. I aim to develop scalable algorithms that enable agents to develop generally intelligent behavior through learning. To this end, my works have targeted key under-explored problems in the field of Imitation Learning, Reinforcement Learning, and Inverse Reinforcement Learning by borrowing tools from a broad range of fields including statistics, computer vision, generative modeling, and sequence modeling. Together with my wonderful collaborators, I have proposed unified algorithms for Imitation Learning in the presence of domain mismatch, proved the identifiability theorems for Markov Decision Processes, and developed state-of-the-art algorithms for Inverse Reinforcement Learning with applications to Robotics and Econometrics. Most recently, I have worked on language models for learning skill abstrations and fractal image compression.
Previously, I graduated first place amongst the class of 2018 from Caltech with a B.S in Computer Science. During my time at Caltech, I was mentored by Joel Burdick, Pietro Perona, and Hyuck Choo. I was also a reseach intern at NASA's Jet Propulsion Laboratory (JPL) advised by Issa Nesnas.
Recent News
- Jan 2023: Bellman Score Estimation paper accepted for spotlight oral presentation at ICLR, 2023. (top 25% of accepted papers)
- Sep 2022: Awarded the JP Morgan PhD Fellowship.
- Sep 2022: Two papers accepted to NeurIPS 2022.
- Sep 2021: Neural Density Imitation paper accepted at NeurIPS 2021.
- Mar 2021: Reward Identification paper accepted for spotlight presentation at ICML 2021.
Understanding and Adopting Rational Behavior by Bellman Score Estimation
[PDF]
Kuno Kim, Stefano Ermon, ICLR 2023 spotlight (top 25% of accepted papers)
Abstract: We are interested in solving a class of problems that seek to understand and adopt rational behavior from demonstrations, i.e reward identification, counterfactual analysis, behavior imitation, and behavior transfer. In this work, we make a key observation that knowing how changes in the underlying rewards affect the optimal behavior allows one to solve a variety of aforementioned problems. To a local approximation, this quantity is precisely captured by what we term the Bellman score, i.e gradient of log probabilities of the optimal policy with respect to the reward. We introduce the Bellman score operator which provably converges to the gradient of the infinite-horizon optimal Q-values with respect to the reward which can then be used to directly estimate the score. Guided by our theory, we derive a practical score-learning algorithm which can be used for score estimation in high-dimensional state-actions spaces.
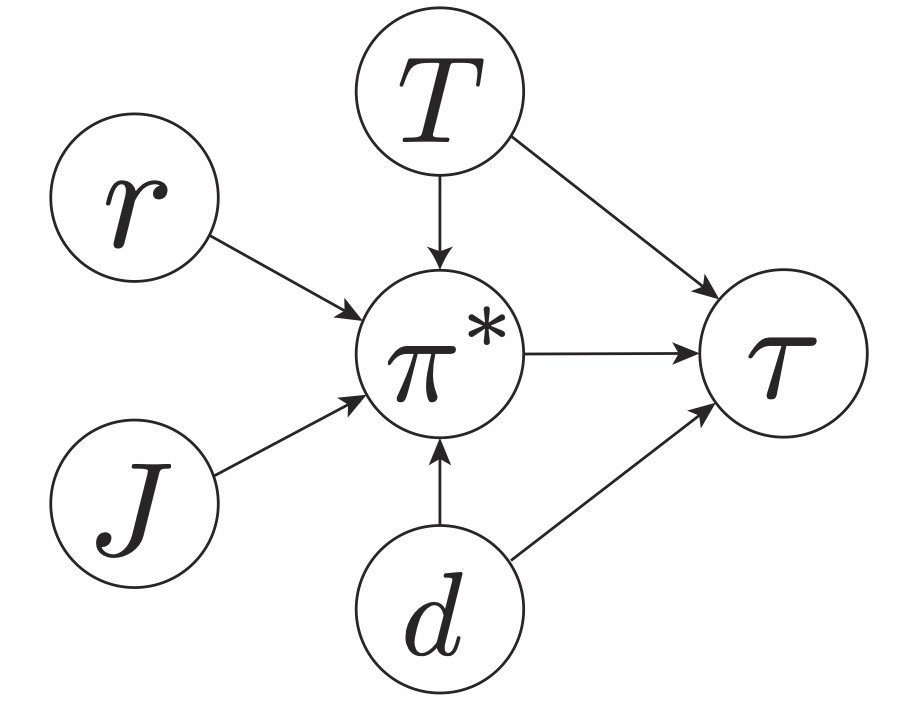
Reward Identification in Inverse Reinforcement Learning
[PDF]
Kuno Kim, Kirankumar Shiragur, Shivam Garg, Stefano Ermon, ICML 2021 spotlight
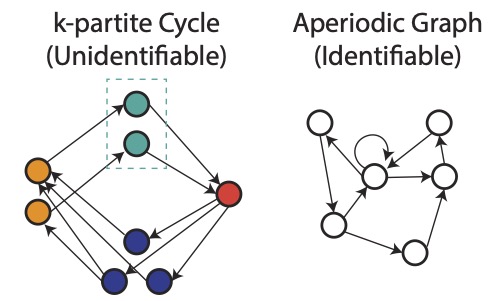
Abstract: The reward identifiability question is critical to answer to know the effectiveness of using Markov Decision Processes (MDPs) as computational models of real world decision makers in order to understand complex decision making behavior and perform counterfactual reasoning. While identifiability has been acknowledged as a fundamental theoretical question in IRL, little is known about the types of MDPs for which rewards are identifiable, or even if there exist such MDPs. In this work, we formalize the reward identification problem in IRL and study how identifiability relates to properties of the MDP model. For deterministic MDP models with the MaxEntRL objective, we prove necessary and sufficient conditions for identifiability. Building on these results, we present efficient algorithms for testing whether or not an MDP model is identifiable.
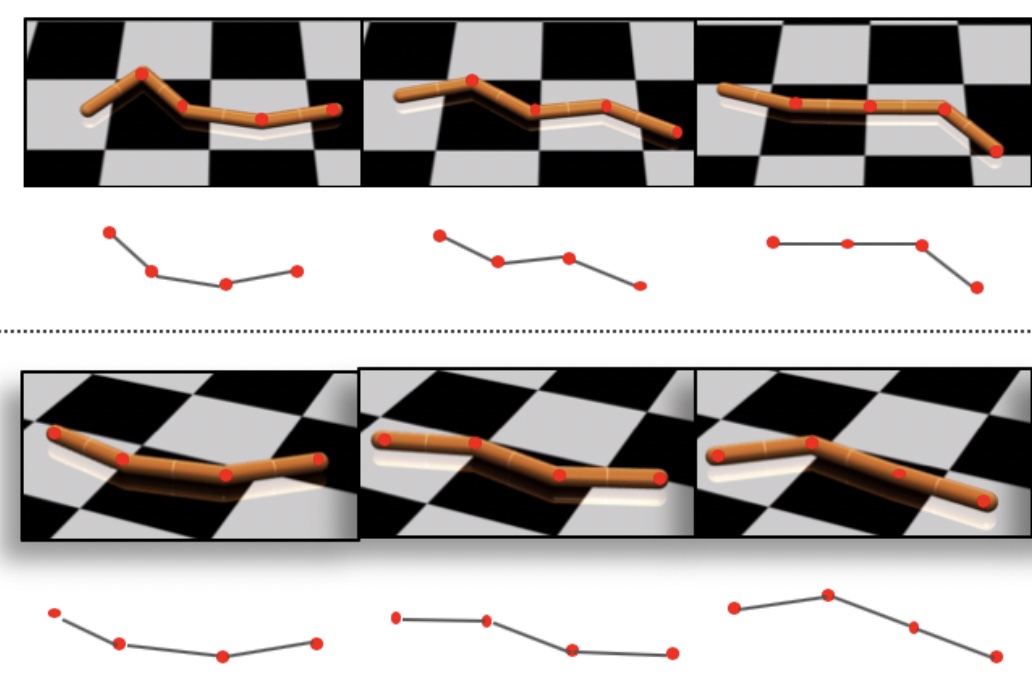
Domain Adaptive Imitation Learning
[PDF]
Kuno Kim, Yihong Gu, Jiaming Song, Shengjia Zhao, Stefano Ermon, ICML 2020 spotlight
Abstract: We formalize the Domain Adaptive Imitation Learning (DAIL) problem, which is a unified framework for imitation learning in the presence of viewpoint, embodiment, and dynamics mismatch. We propose a two step approach to DAIL: alignment followed by adaptation. In the alignment step we execute a novel unsupervised MDP alignment algorithm, Generative Adversarial MDP Alignment (GAMA), to learn state and action correspondences from unpaired, unaligned demonstrations. In the adaptation step we leverage the correspondences to zero-shot imitate tasks across domains. To describe when DAIL is feasible via alignment and adaptation, we introduce a theory of MDP alignability. We experimentally evaluate GAMA against baselines in embodiment, viewpoint, and dynamics mismatch scenarios where aligned demonstrations don't exist and show the effectiveness of our approach.

Active World Model Learning with Progress Curiosity
[PDF]
Kuno Kim, Megumi Sano, Julian De Freitas, Nick Haber, Daniel Yamins ICML 2020
Abstract: World models are self-supervised predictive models of how the world evolves. Humans learn world models by curiously exploring their environment, in the process acquiring compact abstractions of high bandwidth sensory inputs, the ability to plan across long temporal horizons, and an understanding of the behavioral patterns of other agents. In this work, we study how to design such a curiosity-driven Active World Model Learning (AWML) system. We construct a curious agent building world models while visually exploring a 3D physical environment rich with distillations of representative real-world agents. We propose an AWML system driven by gamma-Progress: a scalable and effective learning progress-based curiosity signal and show that gamma-Progress naturally gives rise to an exploration policy that directs attention to complex but learnable dynamics in a balanced manner, as a result overcoming the “white noise problem”.